I want to talk about deploying Azure Data Factory using https://aka.ms/avm Azure Verified Modules, covering the differences and challenges associated with deploying and operating your Data Factory infrastructure vs the actual inner workings of the data factory and the lifecycle of those components.
The takeaway from this article is to always keep your operational components outside of Infrastructure code
For a SQL server for example, you can have IaC that deploys the server, and then you have Visual Studio database solution that can create the databases (or you can use iac for that) but most importantly, you only build your SQL tables, stored procedures, views, schemas and indexes and primary keys and so in the database solution.
In Data Factory, you can have various operations and components such as pipelines, data sets, data flows, linked services, integration runtimes, managed private endpoints, and more. These can be seen as different operational components within Data Factory.
Default stuff that gets deployed with bare bones Factory
- AutoResolveIntegrationRuntime - this is an azure hosted integration runtime. Used to link to other Azure resources like Storage Accounts.
- Uhh, that’s it. Just an empty data factory. No linked services, piplelines or anything. You have to create it. BUT WHERE DO WE DO THAT?
Lets say you wanted to have an Integration Runtime that operated on a Managed Virtual Network that can support private endpoints.
Where do you do that? In Infrastructure as code?
No. Do it in the factory itself, BUT first connect it to Git. See below on how to do create an Azure Integration Runtime with MVN (Managed virtual network)
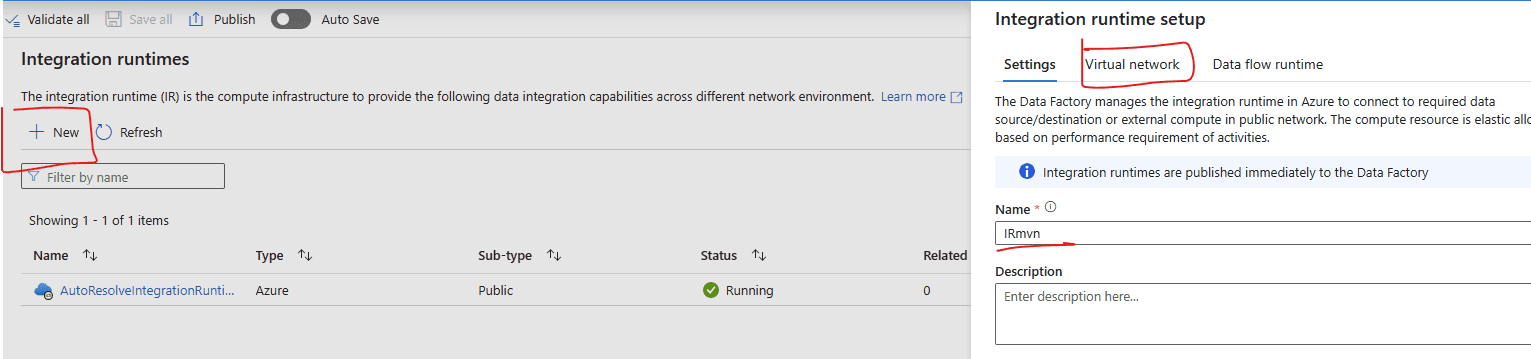
Be sure to enable the virtual network
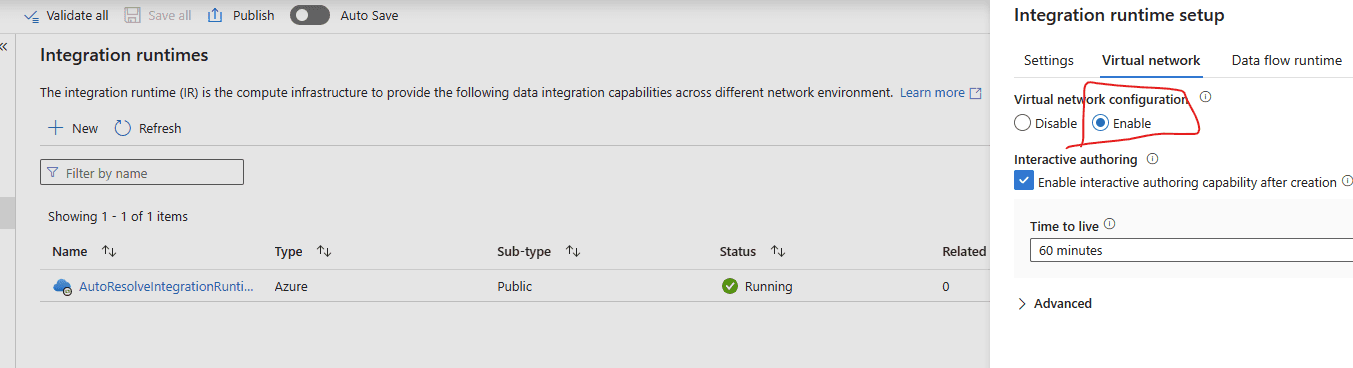
There is an important advantage to this, firstly your infra guys don’t need to worry about building an integration runtime that has a managed virtual network, you can leave that to the data factory developers who will do it with the git code enabled on the factory, and this will help to keep it all in code and deployable.
Here is public GitHub repository I created that describes everything in this blog.
The Problem
As we have discussed, the decision to code your pipelines, managed private endpoints, linked services needs to come early on. Will you use the bicep templates to do this? Or will you let the devleopers create these components inside the factory with the git mode activated?
The answer is to let your ADF developers do it in the factory and then utilise DevOps to build and release the Factory (which emulates the “Publish” button on the Factory)
I am hoping this diagram helps to describe what the factory will look like if you did code some pipelines and global parameters in your IaC.
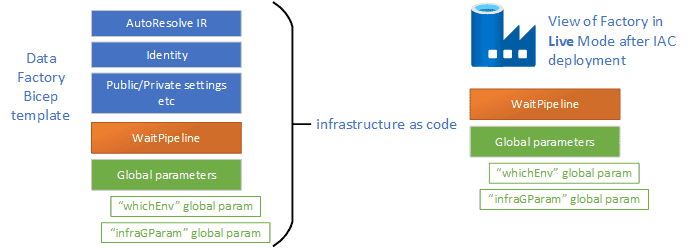
If you are in the Factory and you switch over to the Git Mode you will find that the factory looks like this, and you might ask WHY!?
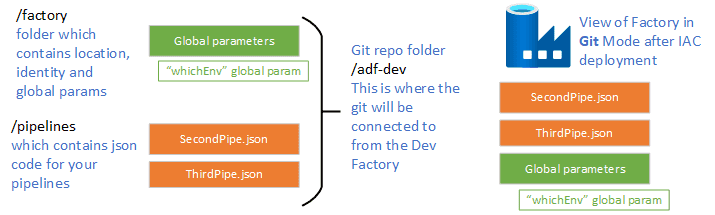
Do you see how different they look? (look at the factory images on the right hand side, different number of pipelines etc)
This is because the factory in the LIVE mode shows what it is in the the IaC and the factory in the GIT mode is what is in the /adf-dev folder (see my github page for more info -> GitHub repository)
How to go about building it the correct way
To get started with AVM, go to http://aks.ms/avm and select the Data Factory module. Follow the instructions provided. For example, when working with large parameter data sets, you’ll find integration runtimes, managed private endpoints, and global parameters included, but beware because this can lead you down the wrong path.
Don’t code your data factory operations in IaC. What are operations? Anything that is specific to a particular business problem that you are trying to solve. Pipelines solve specific business problems and you can have 1-100’s of pipelines in one factory.
Pipelines need datasets, and datasets need linked services and linked services need integration runtimes. Do this all in the Data Factory in the Git mode (or if you are brave enough or tech geeky, code it in Json in the git location folder that is connected to your Factory)
Factory Settings on the other hand are for the entire factory, not to solve specific and different business problems such as ETL processes or data wrangling.
DevOps build and Release
Use DevOps CI/CD to manage the lifecycle of your Data Factory. Don’t use the Publish button, but rather use NPM packages to build your data factory ARM template and then release it, all with DevOps or with GitHub actions. A great article for this is here
Remember, if an infrastructure team member adds anything to your Data Factory that isn’t in the Git folder, and you run your DevOps pipelines, it won’t be deployed to the Live Factory. This highlights the importance of maintaining consistency between your Git repository and the live Data Factory.
After you have built and released, this is what your factory will look like
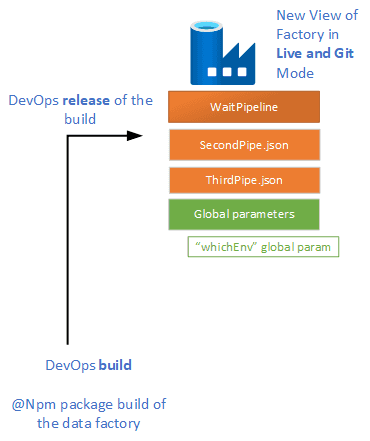
Another valid option is to use “Import” after first successful IaC deployment
If your live factory has parameters or pipelines that aren’t reflected in Git, you can use the Import resources feature in Git configuration tab to import from the live factory to Git. This ensures your Git repository matches your live Data Factory.
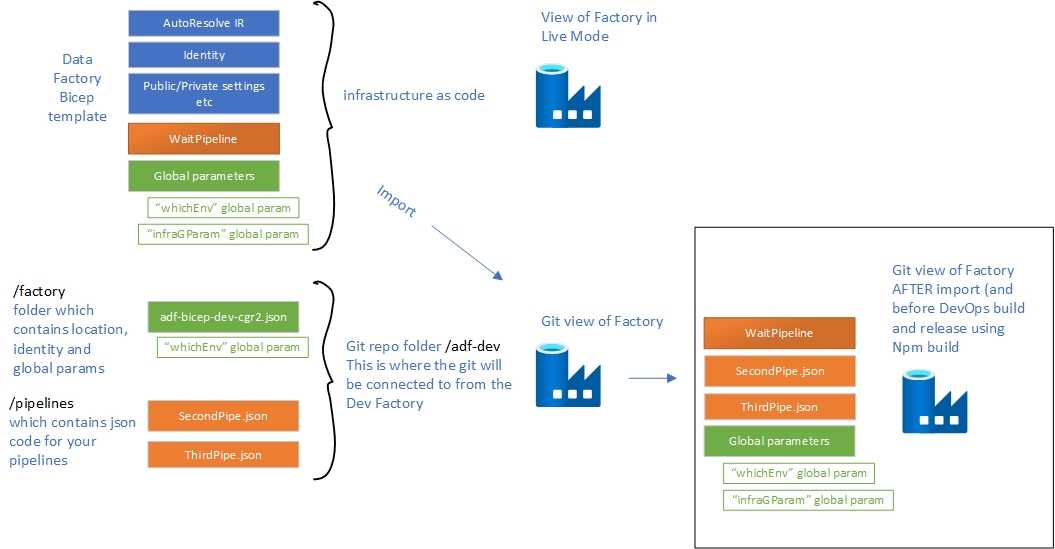
To summarize, deploying Data Factory using infrastructure as code requires careful synchronization between Git and the live environment. Always ensure that changes made in the live factory are reflected in Git to avoid discrepancies.
I hope this clarifies the deployment process and addresses some common issues. Thank you for reading!